去年的工作了,一直没抽出时间整理出来,模型并行看似神秘,在网上搜索相关资料的时候大部也是以谈原理的居多,唯独少了有人拿出代码来捅破这层窗户纸。这里我放出一个PyTorch版本的Demo供大家参考交流。
相关的资料可以参考以下的几个页面:
0x00 什么是模型并行?
一般大家比较常见的并行模式是数据并行,也就是PyTorch里面提供的nn.DataParallel,在使用多卡的时候,会自动在batch_size这个方向上做划分,把计算量分摊到不同的显卡上面。注意在这种模式下面,每张显卡上都有一个完整的模型副本。对于普通的数据集来说这种方式并不会有太大问题,但是在应对人脸识别这种应用时,如果有百万甚至上亿类别的数据量级,这种方式就会有问题了。我们可以简单计算一下最后FC层的参数数量需要占用的显存空间。假设权重以单精度FP32进行存储(需要4个字节),人脸特征维数为512,人脸的类别有1000万,那么最后FC层参数所需要的存储空间大约为19GB左右,这还没有算上网络当中其他参数以及中间结果所需要的空间,以大家目前最常用的显卡GTX 1080 Ti来看,这肯定是装不下的。
刚才我们说了,在多卡数据并行的模式下,每张显卡上都会有一个完整的模型副本,但是我们仔细分析一下就会发现,在FC层上有着很大的改进空间。如果说前面的卷积层部分存在着很复杂的连接和依赖关系,我们无法将很好的将他们划分到不同的显卡的上以节省空间。FC层天生就具备着可划分的属性,他无非就是一个简单的矩阵乘法和加法(有bias的情况下),我们计算0~1000类别的logits和5000~6000类别的logits是完全独立互不影响的。因此,在多卡的情况下,我们完全可以利用这个特性将FC层划分为多个部分分别计算。这样一来,每张显卡存储的模型就变成了:FC层之前的网络副本和FC层的一部分,在刚才的例子中,如果我们用到8张显卡,那么FC层分摊到每个显卡上的存储空间大约只有2GB多,这是完全可以接受的。
但是,说起来容易,真正实践起来还是有不少细节问题需要考虑。我们接着往下分析。
0x01 朴素的模型并行
朴素的模型并行逻辑非常简单,如下所示
class FullyConnected(nn.Module):
def __init__(self, in_dim, out_dim, num_gpu, model_parallel=False):
super(FullyConnected, self).__init__()
self.num_gpu = num_gpu
self.model_parallel = model_parallel
if model_parallel:
self.fc_chunks = nn.ModuleList()
for i in range(num_gpu):
_class_num = out_dim // num_gpu
if i < (out_dim % num_gpu):
_class_num += 1
self.fc_chunks.append(
nn.Linear(in_dim,
_class_num,
bias=False).cuda(i)
)
else:
self.classifier = nn.Linear(
in_dim,
out_dim,
bias=False)
def forward(self, x):
if self.model_parallel:
x_list = []
for i in range(self.num_gpu):
_x = self.fc_chunks[i](x.cuda(i)) # 分别在不同的卡上计算
x_list.append(_x)
x = torch.cat(x_list, dim=1) # 把结果concat起来
return x
else:
return self.classifier(x)
我们只需要根据GPU的数量把FC层划分成若干部分,把计算量分摊到每张卡上,最后把结果concat起来即可;其余部分如CNN抽取特征,以及算loss等都不用作任何改动,看起来一切都很完美,然而在训练时候我们发现,显存占用极为不均衡,0号卡的显存占用比其他卡高出许多。
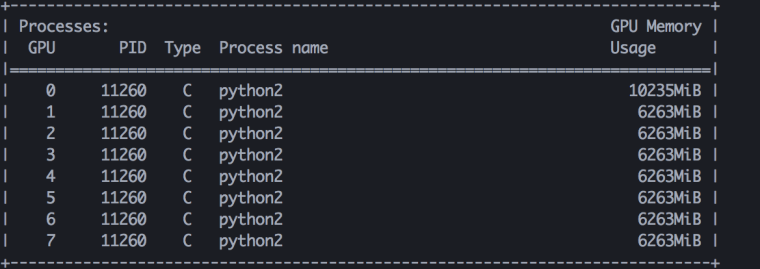
这导致我们很难进一步提高batch_size,为什么0号卡的显存占用比其他卡高出这么多呢?原因在于算loss上的过程上,虽然我们把FC层的计算量分摊到每个卡上了,可是最后依然要concat起来(放在0号卡上),算loss的负担全部落在0号卡上,显存自然居高不下。
有的同学问,算个loss这么吃资源吗?在小数据集上当然看不出来,但如果是上千万量级的类别,在算softmax和交叉熵时分别要做exp和log运算,这个计算成本和开销不容小觑
0x02 显存均衡的模型并行
所以,更优的方案应该避开torch.cat这一步,在不concat的条件下直接去计算loss并实现backward,那么如何去实现呢?这就要求我们对算loss、求导和反向传播的一些细节有所了解了。
我们仔细思考一下刚才说的算loss这个过程,在普通的情况下我们会直接使用PyTorch里面的nn.CrossEntropy来计算loss,这个过程实际上包含了计算softmax和计算cross entropy两个步骤。
计算softmax
我们先来看看softmax怎么处理,softmax的计算公式如下 :
\[p_i=\frac{e^{x_i}}{\sum_{k=1}^N e^{x_k}}\]这里就遇到了第一个难题了,分母需要计算整体的和,而由于我们对FC层做了划分,每张显卡都只有一小部分,怎么办呢?没办法,这里必须要进行一次同步,在PyTorch中不同显卡如何进行信息同步呢?大家可以参考这个文档中的内容,使用torch.cuda.comm提供的函数即可。看起来计算softmax的问题就解决了,如果你直接使用这个公式去计算softmax,训练一段时间后你就会发现loss变成了NAN,为什么呢?因为溢出了……所以说细节是魔鬼啊,目前所有主流的深度学习框架都封装的特别好,把这个细节细隐藏掉了,能够保证数值稳定性的softmax计算应该是下面这样的:
其中$C=\max (x_1,x_2,\cdots, x_N)$,这里用numpy示例一下:
def stable_softmax(x):
z = x - max(x)
numerator = np.exp(z)
denominator = np.sum(numerator)
softmax = numerator / denominator
return softmax
所以,为了保证数值稳定需要我们要额外在多卡之间再同步一次最大值
计算loss
当我们得到softmax的输出之后,接下来就是算loss,然后求导反向传播了,由于我们不能使用PyTorch提供的nn.CrossEntropy,所以我们必须手动计算loss,手动求导。大家不要被所谓的手动求导吓倒,实际上这个过程并不难,而且由于我们使用的是softmax+crossentropy,最终求导得到的输出层(也就是我们常说的logits,softmax前面的那一层)梯度形式简单的出奇,就是softmax输出减去对应的one-hot形式的label,$\frac{\delta L}{\delta o_i}=p_i-y_i$
如果你对这个过程不太清楚,可以参考这个下面这个网页,里面有非常详细的推导过程
这个优雅的表达式有什么好处呢?这意味着我们甚至可以不用计算loss就能直接得到梯度,而且不需要跨卡信息同步,每个卡就能够计算得到自己对应那部分的梯度。
当然,不算loss的话,我们就缺少了训练过程中一个很重要的指示信息,但是由于算loss的值又需要引入额外的通信同步开销,所以我们可以折中一下,每隔10步或者100步计算一次。这里我们额外加上一个compute_loss参数作为flag,指示是否计算loss
反向传播
即然是手动算loss和梯度,那么显然反向传播的过程也要自己动手来写了。在PyTorch当中forward函数大家写的比较多,那么backward函数怎么写呢?首先需要注意的是,backward函数写在nn.Module中是不起作用的,必须要写在torch.autograd.Function里面,详情可以参考这个网页,其次需要注意的是,对应的forward函数中有多少个参数(不包括self),相应的backward函数中就要返回多少个梯度。由于在模型并行当中,我们无法预知使用了几个显卡,所以forward中的参数数量与backward中的返回值数量都是不确定的。
更多细节大家直接看代码就好了:
class ModelParallelCrossEntropy(nn.Module):
def __init__(self):
super(ModelParallelCrossEntropy, self).__init__()
# args[0] is compute loss flag, args[1] is label_tuple
# args[2:] is logit parts
def forward(self, *args):
return ModelParallelCrossEntropyFunc(args[0], args[1])(*args[2:])
class ModelParallelCrossEntropyFunc(Function):
def __init__(self, compute_loss, label_tuple):
self.batch_size = label_tuple[0].size()[0]
self.compute_loss = compute_loss
self.label_split = label_tuple
def forward(self, *args): # args is list of logit parts
# for numerical stability
max_list = []
for arg in args:
m, _ = torch.max(arg, dim=1, keepdim=True)
max_list.append(m)
mc = torch.cat(max_list, dim=1)
m, _ = torch.max(mc, dim=1, keepdim=True)
nargs = [arg - m.to(gpu_id) for gpu_id, arg in enumerate(args)]
# get exp sum
exp_logit_list = []
exp_sum_list = []
for gpu_id, narg in enumerate(nargs):
exp_logit = torch.exp(narg)
exp_logit_list.append(exp_logit)
exp_sum = torch.sum(exp_logit, dim=1, keepdim=True)
exp_sum_list.append(exp_sum)
exp_sum_all = comm.reduce_add(exp_sum_list, 0)
# compute softmax output
softmax_list = []
for gpu_id, narg in enumerate(nargs):
softmax = exp_logit_list[gpu_id] / exp_sum_all.to(gpu_id)
softmax_list.append(softmax)
# save the softmax output, we will need it in backward
self.save_for_backward(*softmax_list)
loss = torch.zeros(1)
if self.compute_loss:
_loss_list = []
for gpu_id, softmax in enumerate(softmax_list):
_loss = torch.sum(softmax * self.label_split[gpu_id], dim=1)
_loss_list.append(_loss)
_loss = comm.reduce_add(_loss_list, 0)
log_loss = -torch.log(_loss)
loss = torch.mean(log_loss)
return loss
def backward(self, loss_grad):
grad_logit_list = []
for gpu_id, softmax in enumerate(self.saved_variables):
grad_logit = (softmax - self.label_split[gpu_id]) / self.batch_size
grad_logit_list.append(grad_logit)
return tuple(grad_logit_list)
使用这个版本的模型并行后,显存如下所示,显存使用不均衡的问题得到了有效缓解
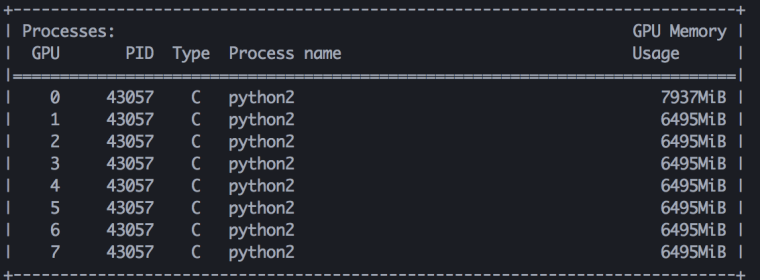
甚至训练速度也有略微的提升,在朴素的模型并行中,我们需要把其他每个卡的输出concat到0号卡上,相当于做了一次同步,通信同步的信息量(每个卡的logits)其实是非常大的。而使用模型并行后,我们虽然做了两次同步,但是每次同步的信息量都非常小,第一次是一个最大值,第二次是一个部分和。
0x03 和其他魔改loss相结合
刚才的说的模型并行过程都是在简单的FC层上,基于softmax+crossentropy实现的,那么在实际的应用场景中,比如人脸和行人重识别都会用到一些更为复杂的loss,比如Large-Margin Softmax、ArcFace、CosFace、SphereFace、AM-softmax等等。那么模型并行能够在这些方法上适用吗?
实际上,我们只要简单分析一下这些方法的细节会发现:上面列举的那些魔改的loss,本质上是对FC层及其输出的logits做了一些带trick的修改(目的是为了增加训练难度,增大类间间距),实际上后面的softmax和crossentropy计算与上一小节是完全一致的,所以我们实现的模型并行版的CrossEntropy依然可用,完全可以和人脸中的各类魔改loss兼容。这里我以AM-softmax为例进行说明(为什么不用其他的?因为AM-softmax写起来最简单……)
class FullyConnected_AM(nn.Module):
def __init__(self, in_dim, out_dim, num_gpus=1, model_parallel=False, class_split=None, margin=0.35, scale=30):
super(FullyConnected_AM, self).__init__()
self.num_gpus = num_gpus
self.model_parallel = model_parallel
if self.model_parallel:
self.am_branches = nn.ModuleList()
for i in range(num_gpus):
self.am_branches.append(AM_Branch(in_dim, class_split[i], margin, scale).cuda(i))
else:
self.am = AM_Branch(in_dim, out_dim, margin, scale)
# 非模型并行情况下,labels为one-hot形式
# 模型并行情况下,labels是一个list,里面每个元素是labels的one-hot形式的一小部分(按class方向划分、且已经在对应的显卡上),concat起来就是完整的one-hot形式label
def forward(self, x, labels=None):
if self.model_parallel:
output_list = []
for i in range(self.num_gpus):
output = self.am_branches[i](x.cuda(i), labels[i])
output_list.append(output)
return tuple(output_list)
else:
return self.am(x, labels)
class AM_Branch(nn.Module):
def __init__(self, in_dim, out_dim, margin=0.35, scale=30):
super(AM_Branch, self).__init__()
self.m = margin
self.s = scale
# training parameter
self.weight = nn.Parameter(torch.Tensor(in_dim, out_dim), requires_grad=True)
self.weight.data.uniform_(-1, 1).renorm_(2, 1, 1e-5).mul_(1e5)
# 这里的label必须是已经转换为one-hot形式
# 如果是模型并行下,label是one-hot形式的一部分,且位于对应的显卡上
def forward(self, x, label):
x_norm = x.pow(2).sum(1).pow(0.5)
w_norm = self.weight.pow(2).sum(0).pow(0.5)
cos_theta = torch.mm(x, self.weight) / x_norm.view(-1, 1) / w_norm.view(1, -1)
cos_theta = cos_theta.clamp(-1, 1)
phi = cos_theta - self.m
index = label.data
index = index.byte()
output = cos_theta * 1.0
output[index] = phi[index]
output *= self.s
return output
得到输出后,依然是用前面的ModelParallelCrossEntropy进行计算即可。
0x04 说明
我之前是做行人重识别相关工作的,由于这个代码是Demo性质,我只保留了核心的模型并行部分(从完整项目中剥离出来的),脚本中只有几个最基本的参数,大家对照着train.py看就可以了。需要说明的是num_classes这个参数,默认应该是从数据集中获取的,但是公开的行人数据集中没有能达到几十万上百万量级的,所以这个参数可以手动设定一个比较大的值,这样后几张显卡相当于在做无用功,不过用来测试效果还是可以的……
测试的数据集推荐使用Market,当然如果想使用人脸的数据集也是可以的,修改一下输入预处理和模型的一些尺寸就可以了
假设使用四张GTX 1080 Ti显卡,类别数为300万,使用模型并行和AM-softmax,训练的命令如下:
python train.py --gpus=0,1,2,3 --data_path=/your/data/path --num_classes=3000000 --am --model_parallel
如果不使用model_parallel选项的话,肯定会报OOM错误,大家也可以自行对比一下与朴素的模型并行相比在显存占用上的区别。
项目地址:https://github.com/bindog/pytorch-model-parallel
如果觉得本文对您有帮助,欢迎打赏我一杯咖啡钱~
