背景
混合精度训练出现了有好几年的时间了,由于前东家的卡是老古董的GTX 1080 Ti,不支持FP16,一直没有时间真正用起来。刚好最近有朋友反馈混合精度训练在之前的模型并行上有点问题,所以跟进研究了一下
当然,本文不仅是修复了一些小问题,同时也分析了混合精度训练中所使用的一些技巧原理
混合精度训练
如果训练使用的框架是pytorch,那么首选的应该是N厂的apex,经过好几年的迭代,目前的apex使用起来已经非常傻瓜,基本上能用的trick全都已经集成了,看一遍README里面的示例就知道怎么改造自己的程序了。
刚才提到混合精度训练中的trick,这篇论文是必读文献,里面囊括了几个非常重要的trick:FP32 master copy of weights和loss scaling等
其实本质都是一样的:因为半精度的数值表示范围比单精度要小很多,所以需要从各个方面来减小累积误差(FP32 master copy of weights),充分利用FP16的表示范围(loss scaling),必要时使用FP32来进行计算(尤其是一些极其容易溢出计算如exp)
-
FP32 master copy of weights,这个方法起因是大数加小数会引起的误差,我们知道浮点数在计算机中的表示是指数和尾数的形式,在计算过程中包含对阶、尾数运算、规格化、舍入处理、溢出判断几个步骤,而在对阶过程中,若两数相差较大,很容易产生误差。FP32的表示范围较宽,而FP16表示范围较小,因此有一些在FP32表示范围下不会出现问题的加减运算,在FP16下就会出现误差,由此诞生了这样一个方法:即在前向传播和反向传播过程中,使用的均为FP16,而在
optimizer.step()这一步中,将梯度转换为FP32,并与FP32 master copy of weight做运算更新权重,下一次前向计算时,再从FP32 master copy of weight中取值转换为FP16计算,重复上述过程。图示如下: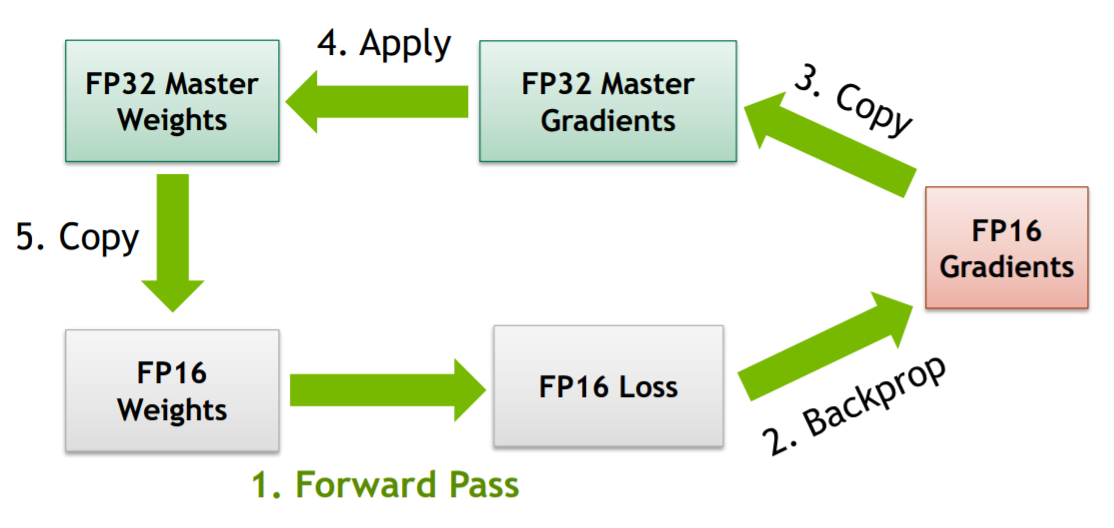
-
loss scaling,这个方法是通过统计得出来的,据论文作者观察,大量梯度的值集中在如下的这个区间内,几乎浪费了FP16一半以上的表示范围,同时有大量值出现了下溢的情况,直接变为0。
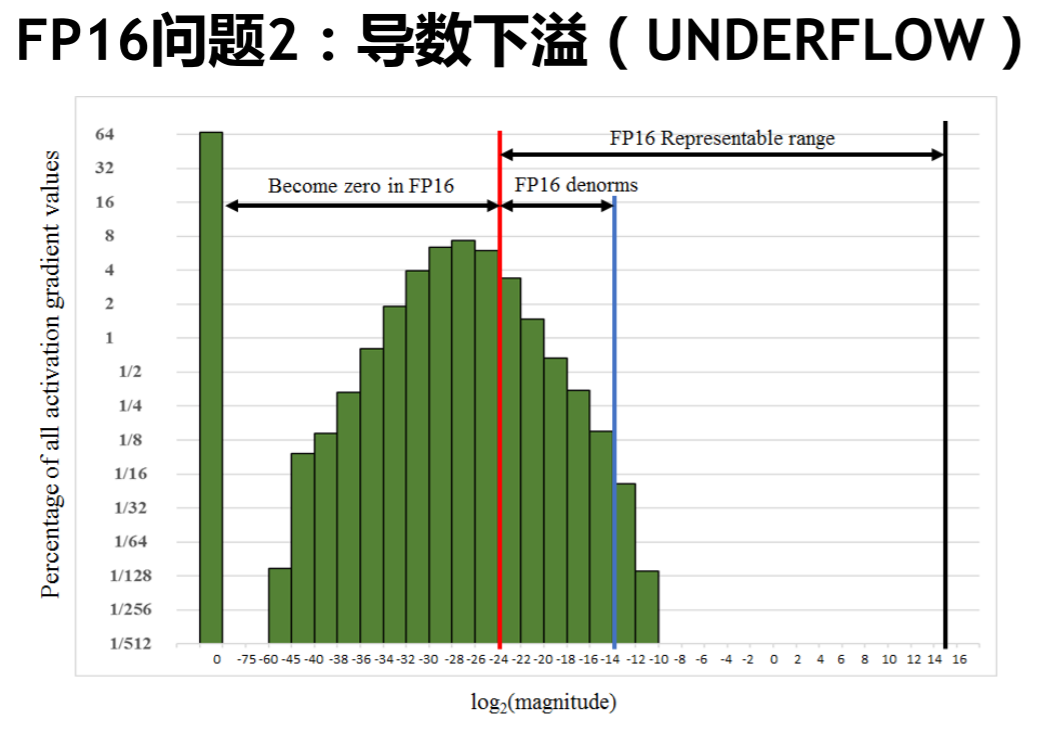
所以有必要人为的对梯度进行放大,充分利用FP16的表示空间,这正是loss scaling的目的,对最终的loss乘以一定的scale(可设置为一个常数,可根据实际情况统计得出,也可动态调整),根据链式求导法则,我们实际上对计算链路中所有的梯度均做了放大。接下的步骤就是与第一个方法相结合,将scale后的FP16梯度复制成FP32再做unscale,最后与FP32 master copy of weights累加即可。整个过程如下所示:
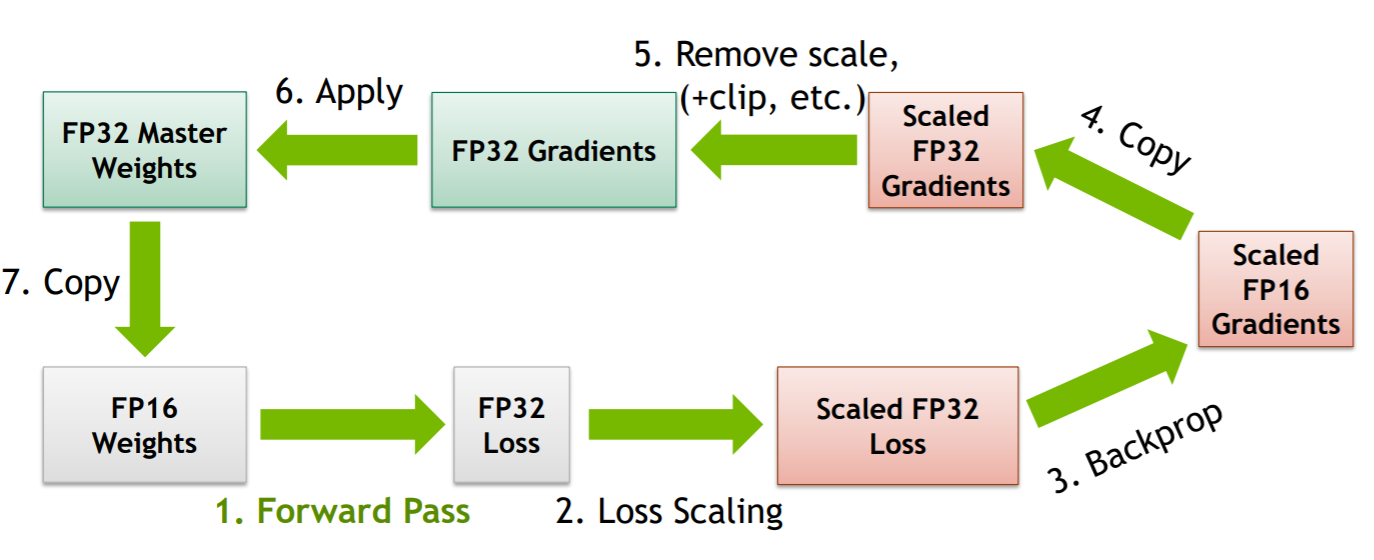
上述内容是对于底层实现原理层面的解释,在使用上apex封装的非常傻瓜了,使用样例如下所示:
# Initialization
opt_level = 'O1'
model, optimizer = amp.initialize(model, optimizer, opt_level=opt_level)
# Train your model
...
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
...
正常情况下,如果定义的模型没有引入一些第三方外部模块,都是常见的一些网络的话,那么使用起来是没有什么总是的。但如果使用了一些外部模块(CUDA实现的一些新算子等)不支持FP16,那么我们需要对相应的函数做一些标记注册@amp.float_function,典型的例子如这个DCN实现
至此,基本的混合精度训练就介绍完了,下面聊聊在改造模型并行程序适配混合精度训练中遇到的一些问题。
模型并行改造
对之前模型并行不熟悉的同学可参考这篇文章:如何支撑上亿类别的人脸训练?——显存均衡的模型并行(PyTorch实现)
改造过程主要涉及三部分,一是由于pytorch在1.3.0版本后仅支持@staticmethod形式的torch.autograd.Function,所以需要对之前所写的ModelParallelCrossEntropy进行重写,二是由于ModelParallelCrossEntropy所处的位置非常尴尬,它不属于深度学习网络的一部分,也不包括任何参数,是最后计算loss的模块,因此有些操作不能靠apex自动完成,需要手动加上;三是一个细节优化,在原来的实现中,one-hot label也是一个显存消耗大户,尤其是label数量到达百万级别后,这里我们使用sparse tensor对其进行优化。
重写@staticmethod
pytorch官方文档中有专门的一篇教程说明如何自定义一个新的Function,注意和原来实现的主要区别在于:
- 没有了初始化函数__init__
- forward和backward函数均为
@staticmethod - forward和backward函数中原来的
self由ctx替代,功能类似
注意,由于没有了初始化函数,我们无法在初始化的时候传入一些控制参数,如显卡数量、是否计算loss等,只能在forward的时候将其传入(forward只接受tensor类型参数,布尔型等参数需要根据情况进行转换),在backward的时候,对这些参数我们也需要返回其梯度(None即可)
backward中的问题修复
文章开始说的模型并行的问题主要是由于scale_loss引起的(如果不使用scale_loss是可以正常收敛的,但是最终效果会差一些),根据前面的原理讲解我们知道:scale_loss是通过链式求导法则将最后乘在loss上的scale反向传播到整个网络中的梯度中去的,而我之前那个版本实现的backward是有问题的,假定了loss是整个计算图的最后一个操作,并未考虑到scale这种情况,导致整个网络中的梯度并没有被放大,训练也就无法进行下去(非常羞愧……);解决过程并不复杂,核心在于理解backward的机制和参数含义,在之前的那篇文章中提到过,forward的返回值要与backward的参数一一对应,forward的参数要与backward的返回值一一对应,如下图所示:
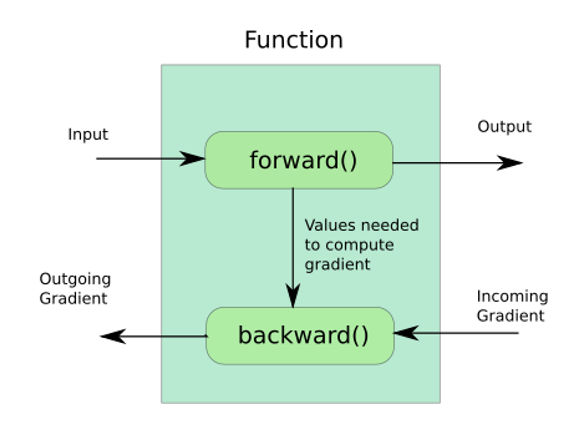
那么在ModelParallelCrossEntropy这个Function中,我们之前忽略掉的backward的输入参数loss_grad到底是什么?结合前面的描述和配图,仔细思考一下就清楚了:forward时最终输出的是loss,而在混合精度训练情况下后面还有一步,即scaled_loss=loss*scale,那么backward时,loss_grad=d(scaled_loss)/d(loss)=scale;所以在计算完梯度后,根据链式求导法则,我们需要把原梯度乘上scale才能保证结果的正确性,修复了这里在混合精度下即可正常收敛了。
这里再提一句,backward本身支持一个grad_tensors参数,相当于人为的传进去一个梯度,在某些特殊的情况下是有用的,例如forward输出的值为一个向量Tensor,更多细节可参考这篇知乎专栏
使用sparse tensor
原先在生成one-hot label tensors时,参考的是pytorch官方论坛上的一个实现,当时并未多想,实际情况若label数量到达百万级别,one-hot label也是一个显存消耗大户,因此考虑使用sparse tensor对其进行改造。然而由于torch.sparse仍然不成熟,许多操作如scatter并不支持,所以需要我们手工的去做分片操作,这就纯属体力活了不用细讲了,直接看代码即可
总结
本次改进的更新仍在原来的repoapex_debug分支下,后续有更好的思路我也会持续更新,也欢迎大家提issue
如果觉得本文对您有帮助,欢迎打赏我一杯奶茶钱~
