最近在做Kaldi相关开发的过程中,遇到了一个非常棘手的内存问题,现将整个排查解决过程梳理一下,希望对有类似问题的同学有帮助。
0x00 情况概述
Kaldi是一个语音识别的C++开发框架,集成了非常多的工具和模块。由于项目需要,希望能够将CVTE开源的模型部署到内部线上测试使用,且能够充分利用GPU加速,而网上的教程大多都是基于offline模式,使用的是nnet3和nnet3bin下面的模块和程序。
当然其中nnet3bin也有一个使用了GPU显卡的示例程序nnet3-latgen-faster-batch,但它并不是一个充分利用GPU计算的实现,整体还是比较低效的。NVIDIA的工程师在今年GTC19上开源了他们的实现,但是想要将CVTE模型在这个版本的实现上跑起来,需要定制化的做一些开发,具体的hacking过程就按下不表,我们的主题是排查内存的泄漏问题。程序运行起来之后,一个很显著的问题是内存占用太高了,在原来的nnet3-latgen-faster-batch下占用内存差不多在17G左右,不会超过20G,而在使用了NVIDIA这个版本后,内存占用一度超过了35G,峰值甚至在40G以上,而且随着需要识别音频不断被输入进来,内存占用还在缓慢的上升。所以,非常有必要解决其中隐藏的内存问题。
0x01 排查过程
经过一番搜索,在Linux下常用的内存泄露检查工具箱是valgrind,这是一个非常强大的工具,光说明使用手册就有400多页。
比较傻瓜的使用方式是直接使用valgrind下面的memcheck工具,当然这个工具并不是万能的,在Kaldi这种比较复杂庞大的工程下面,想要定位出问题所在并不容易;所以我所使用的工具是massif,它能够在程序执行的过程中截取快照,记录每个快照当中,程序内存的详细使用情况,精确到哪个模块的哪一行代码申请占用了内存。
valgrind的简单使用
安装配置过程可参考这个链接,如果没有权限的话,安装到自己目录后配置好环境变量即可使用
执行命令
# 说明
# ./后面可以跟你需要tracking内存的程序及其参数
# 注意这个模式下只tracking堆内存,如果想要记录所有内存情况,需要加上一个--page-as-heap选项
# threshold表示追踪的最低的内存百分比,例如设为1.0表示占比在1.0%以下的内存就不记录了
# time-unit是一个比较迷的参数,影响的是最后画出内存变化趋势图,可选单位的有时间(ms)、指令数(默认)、内存量(B)
# massif-out-file指定输出的文件名
valgrind --tool=massif --threshold=0.0 --time-unit=ms --massif-out-file=memory_footprint ./batched-wav-nnet3-cuda config.yaml
# valgrind提供了一个命令行版的可视化工具,可以简单查看刚才的tracking结果文件
# 如果使用的是带可视化界面的Linux,可以使用相应的图形化工具
# 这里我们把结果输出到一个文本文件里面,以便后续分析
ms_print memory_footprint > vis.txt
基本的情况如下所示,可以看到堆内存随时间的变化情况,下面还有详细的每个snapshot内部的内存分部情况
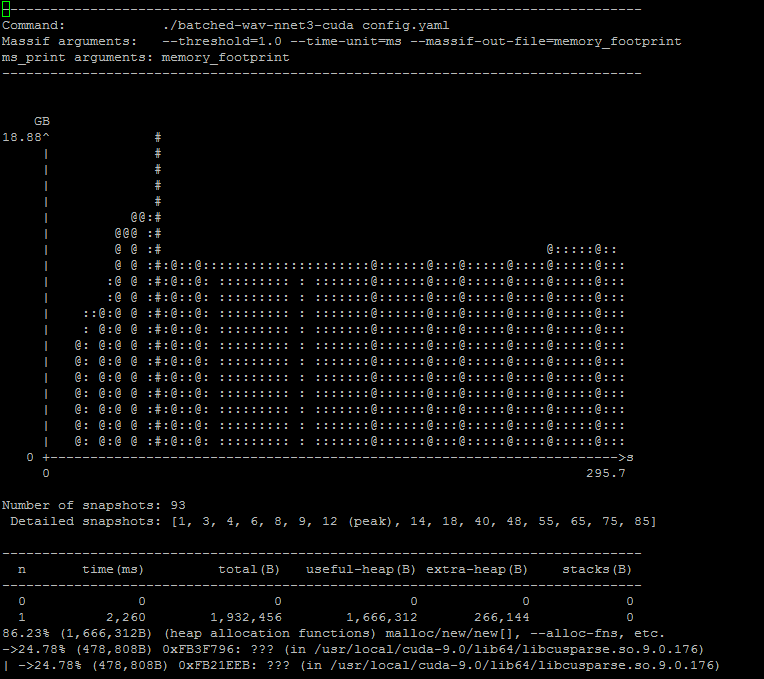
一个详细的snapshot内存记录如下所示:
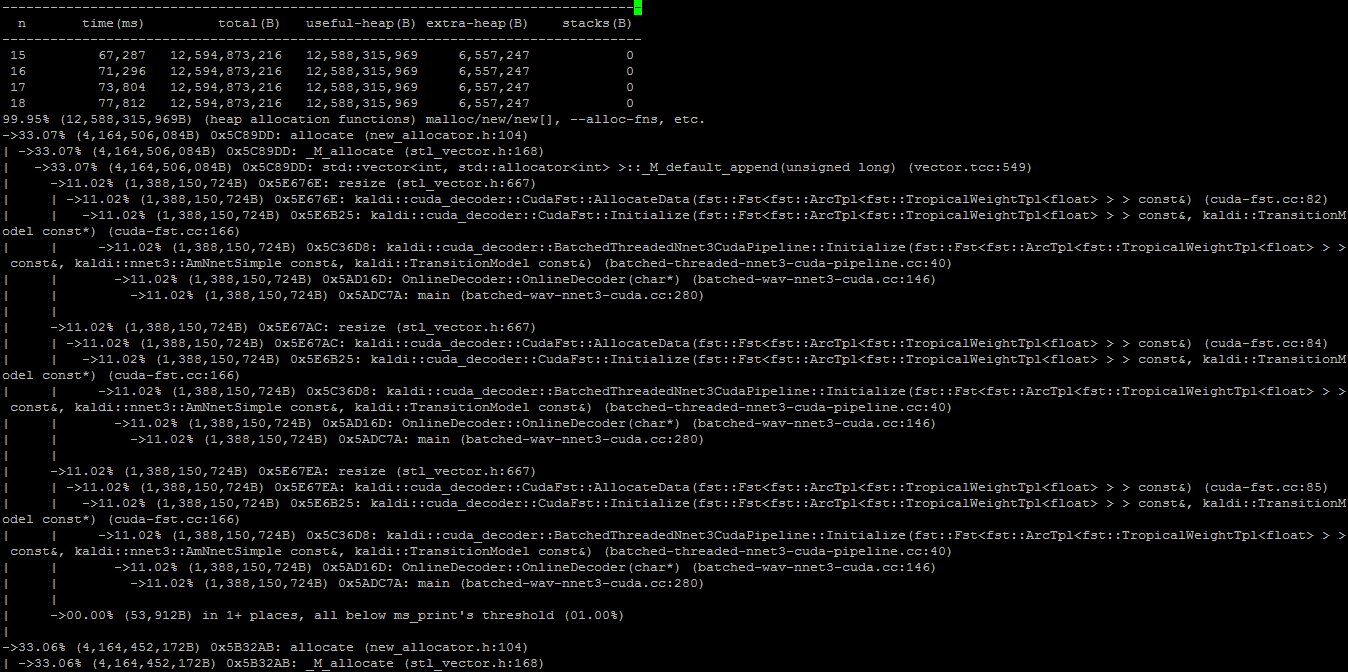
只要在编译C++程序的时候加上了-g选项,就可以从这里详细的看到是程序的哪一行代码申请占用了内存;例如上图有好处几resize函数,那么很显然就是std::vector里面的resize函数申请占用了内存
正确释放STL当中vector的内存
在这个工具的帮助下,我很快定位到了一类比较常见的问题。只需重点关注std::vector的reserve和resize这两个函数,如果某行代码通过这种方式申请了内存,在后续的稳定运行过程中又没有用到,且在程序快结束的时候依然占用着,那么这就是一个可以改进的点了。
这类问题网上一搜就能找到很多,主要是vector的STL实现当中函数名太有误导性了
std::vector<obj> test = ...;
...
test.clear();
很多人以为调用了clear函数之后,其占用的内存空间就自然而然的释放掉了,其实不然,vector当中有一个capacity的概念,调用clear函数只是使用vector的size变为了0,而其capacity没有变化,也就是所占用的内存没有发生变化,正确的释放方式如下:
std::vector<obj>().swap(test);
当然,在C++11当中,我们又多了一种选择
test.clear();
test.shrink_to_fit();
在NVIDIA工程师的实现当中,有好几处类似这种没有正确释放vector内存的情况,一一更正之后内存占用下降到了30G左右。由于这部分不是本文的重点,具体的截图就不贴出来了。
堆内存碎片无法释放
接下来的这个问题就非常诡异了,为了说清楚情况,我先简单介绍一下NVIDIA这个GPU实现和原来的相比有什么区别改进。
语音识别的流程大体上可以分为三个步骤(本人非专家,可能不严谨,只是从代码的角度叙述),第一步是计算抽取声学特征(features),第二步是根据声学特征inference(NBatchCompute),第三步是解码过程(decode),这个过程比较复杂也是最耗时耗内存的部分。在解码的时候有用到一个非常大的文件HCLG.fst,可以把它理解为一个非常庞大的状态转移图,解码的过程就是在这个状态图当中搜索的过程。
在原来的非GPU版本中,kaldi使用了openfst来读取并存储这个状态转移图;而在NVIDIA实现的GPU版本中,依然是先用openfst读取并存储这个状态转移图,但是随后会转换成自己实现的一个cudafst,用于在GPU上进行高效的解码。显然,在后者的解码过程当中,openfst那部分所占用的内存应该是完全不需要的,然而从htop中观察到的内存占用情况却晰的表明,在代码中显示的使用delete xxx(xxx为openfst对象)并没有产生任何效果,也就是说相应的内存并没有被释放掉?于是我又使用valgrind再跑了一次,诡异的事情发生了,在valgrind的结果里面显示,openfst那部分内存是被释放掉了,可同时在htop里面观察到的结果依然是内存占用居高不下,这个矛盾的结果让我卡了很久。
折腾了很久之后,我瞎折腾把openfst对象里面的状态转移图简单log了一下,于是发现了一个很有意思的事情:所谓的状态转移图在代码层面,是一个有长度为1亿多的std::vector,里面存储的是对象指针,每个对象指针指向的对象又包含着一个小std::vector,每个大小不固定,徘徊在2~60之间
但是这个发现并没有直接帮助我解决问题,我在瞎折腾时尝试了另一种方法,delete掉openfst之后,再次创建一个同样的openfst对象,并观察htop中的内存占用情况,在这个情况下,delete之后,内存占用没有减少,而创建一个新的openfst对象,内存几乎没有发现变化,因此这个尝试告诉我们:内存并非没有释放,而是由于某种原因没有返还给操作系统,依然由程序自身占用并管理着
于是,我又有针对性的在网上做了一番搜索,找到了解决方案。相关的资料我列在这里供大家参考:
- https://stackoverflow.com/questions/10943907/linux-allocator-does-not-release-small-chunks-of-memory
- https://www.cnblogs.com/lookof/archive/2013/03/26/2981768.html
简单来说,“罪魁祸首”正是glibc的一个默认机制:非常小的内存块在释放时不返还给操作系统,而由程序自己管理,下次需要使用时直接分配,无需再向操作系统申请。这个机制的出发点的是好的,为了提高效率嘛,毕竟调用操作系统API没有那么高效,何况一个普通的程序产生的内存碎片并不会太多,影响也无伤大雅。谁知道Kaldi所使用的这个openfst产生的内存碎片有1亿多份,加起来总量有10多个G,而且几乎全部在阈值以下,全都没有释放掉……
(ps:在Linux下,malloc()/free()的实现是由glibc负责的。这是一个相当底层的库,它会根据一定的策略,与系统底层通信(调用系统API)。因为glibc的这层关系,在涉及到内存管理方面,用户程序并不会直接和linux kernel进行交互,而是交由glibc托管,所以可以认为glibc提供了一个默认版本的内存管理器。它们的关系就像这样:用户程序 —> glibc —> linux kernel)
解决方法也非常简单,只需要在原来的代码中加一行malloc_trim(0)(依赖malloc.h)即可,这行代码会将刚才所有的内存碎片返还给操作系统。
多线程中的陷阱
前面我们说到还有一个问题是随着程序的运行,内存会不断增长,显然也是某个地方内存未被释放累积引起的,但是遗憾的是,观察valgrind的tracking结果之后发现,这部分内存不是在堆上,而是在栈上。而下面的这个问题需要我们深入到代码层面,逐步调试。
具体的方法其实难度不大,但是对耐心要求较高……这里我所使用的方法是gdb外加watch监视内存变化。
# 先启动gdb
gdb ./batched-wav-nnet3-cuda config.yaml
# 打开另外一个shell 可以利用tmux的panel,这样在同一个界面里比较容易观察
watch -n 0.1 -d cat /proc/[pid]/statm
# statm显示的结果的含义(注意这里的单位是页,也就是4KB,换算内存占用的时候要乘以4)
# size (1) total program size
# (same as VmSize in /proc/[pid]/status)
# resident (2) resident set size
# (same as VmRSS in /proc/[pid]/status)
# share (3) shared pages (i.e., backed by a file)
# text (4) text (code)
# lib (5) library (unused in Linux 2.6)
# data (6) data + stack
# dt (7) dirty pages (unused in Linux 2.6)
# 上面的几个结果,我们重点关注第二项resident即可
如果目标程序是一个单线程的程序,那么这个方法可以说是非常perfect的,哪一行代码申请占用了内存,所见即所得。
遗憾的是,我们面对的程序是一个多线程程序,所以使用gdb的step和continue调试当前线程的时候,其他线程也是同步执行的;也就是说如果你发现监视窗口当中内存占用增加了,那并不一定是当前代码引起的……所以我们在调试当前线程时,必须锁定其他线程,如下
set scheduler-locking off|on|step
# off 不锁定任何线程,也就是所有线程都执行,这是默认值。
# on 只有当前被调试程序会执行。
# step 在单步的时候,除了next过一个函数的情况(熟悉情况的人可能知道,这其实是一个设置断点然后continue的行为)以外,只有当前线程会执行。
但是这个方案并不完美,我们面对的这个多线程程序涉及到多个队列,如果锁死了其他线程,某些前置的任务没有放进队列,当前调试的线程也会卡住不动。总之,需要来回切换,非常折磨耐心,在一番折腾之后总算是定位到了问题所在,问题还是出在和STL相关的地方,std::unordered_map里面存储的任务状态未被释放引起的。
更多gdb调试的tips可以参考下面这个文章
- https://coolshell.cn/articles/3643.html
0x02 更进一步?
当然,如果我们仅仅于满足解决几个小问题是远远不够的,我们希望的是掌握一套方法论,在面对同样甚至更复杂问题时能够有条理和步骤的各个击破。现在问题来了,valgrind的massif工具是自己决定在程序的哪个阶段做snapshot,这个粒度是非常粗线条的。而单独使用gdb的话又不能充分利用valgrind的优势,只能单步慢慢分析,还要面对多线程的难题,效率低下。有没有一种方法,能够像外科手术一样精确,比如执行到某行代码时停住,然后用valgrind做snapshot,并用于后续对比分析?
这个时候如果仔细阅读一下valgrind的说明文档,就会发现这个工具的强大远远超出你的想像。valgrind集成了一个vgdb工具,能够很好的和gdb配合起来,在调试程序的过程中,利用gdb步进到需要snapshot的位置,利用内置的命令即可snapshot,具体操方式如下所示:
# 基本命令和刚才类似,使用vgdb需要加入--vgdb=yes和--vgdb-error=0选项
valgrind --tool=massif --pages-as-heap=yes --threshold=0.0 --time-unit=ms --vgdb=yes --vgdb-error=0 --massif-out-file=memory_footprint ./batched-wav-nnet3-cuda config.yaml
# 执行以上命令后,会启动vgdb,同时出现一行提示信息,类似
# target remote | /path/to/your/vgdb --pid=xxxxx
# 这个命令等下需要用到
# 启动另一个shell,执行
gdb ./batched-wav-nnet-cuda
# 然后再执行刚才的命令
target remote | /path/to/your/vgdb --pid=xxxxx
# 然后就可以像调试正常程序一样下断点、步进、步过等等
# ……
# 当我们到达需要做snapshot的位置时
# 在gdb的shell里面输入
monitor detailed_snapshot [file_name]
# 就可以将当前状态下的内存快照保存下来
当我们有了几个需要重点关注的状态的内存snapshot以后,即可通过diff命令找出发生变化的地方,再进行具体的分析。
有了这样一套强大的分析工具和流程,我觉得在面对大多数内存泄漏问题时,只要有足够的耐心, 一定能够准确定位到有问题的代码部分~
如果觉得本文对您有帮助,欢迎打赏我一杯咖啡钱~

参考资料
- https://stackoverflow.com/questions/10943907/linux-allocator-does-not-release-small-chunks-of-memory
- https://www.cnblogs.com/lookof/archive/2013/03/26/2981768.html
- https://coolshell.cn/articles/3643.html